В свете событий с уходом Atlassian из России, многие компании экстренно мигрируют данные из облачных продуктов в серверные на своей инфраструктуре. Вроде бы, ничего сложного такое переезд не предвещает: в облаке есть кнопка «Create backup for server», на сервере «Restore system» и всё должно заработать из коробки. Но практика показывает, что в этом процессе много подводных камней, о которых я и хочу написать в этом посте.
Для начала важно отметить, что облачные и серверные версии Jira хоть и называются одним именем, но уже лет 6-7 развиваются в Atlassian независимыми командами для абсолютно разных потребителей:
- Cloud-продукты интересны небольшим компаниям без собственной ИТ-инфраструктуры и штата админов,
- Data Center-продукты (они же Self-hosted или On-premise) интересны большим enterprise-компаниям (обычно от 500 сотрудников), которым важно хранить данных Jira в своей корпоративной сети.
То же относится и к плагинам для Jira: некоторые поддерживают либо только Cloud, либо только Data Center. Многие плагины поддерживают оба варианта, но могут отличаться по функциональности, и не всегда имеют удобный механизм миграции между этими вариантами (как понимаете, миграция плагинов не входит в стандартные механизмы миграции Jira и всегда делается индивидуально для каждого плагина).
Кроме того, в Jira Cloud даже есть два типа проектов:
- классические Company-managed projects, когда для гибкой настройки нужна помощь администратора,
- новые Team-managed projects (они же Next-gen projects), которые уступают классическим в наборе функций, но позволяют производить настройку своими силами, без помощи администратора (как понимаете, этого типа проектов нет в Jira Data Center).
Таким образом, для приземления облачной Jira нужно сделать три шага:
- внутри облака конвертировать проекты Team-managed в Company-managed,
- мигрировать Company-managed проекты из облака на сервер,
- мигрировать данные всех плагинов из облака на сервер.
Пункт 1 на первый взгляд выглядит избыточным, но на практике приходим к тому, что:
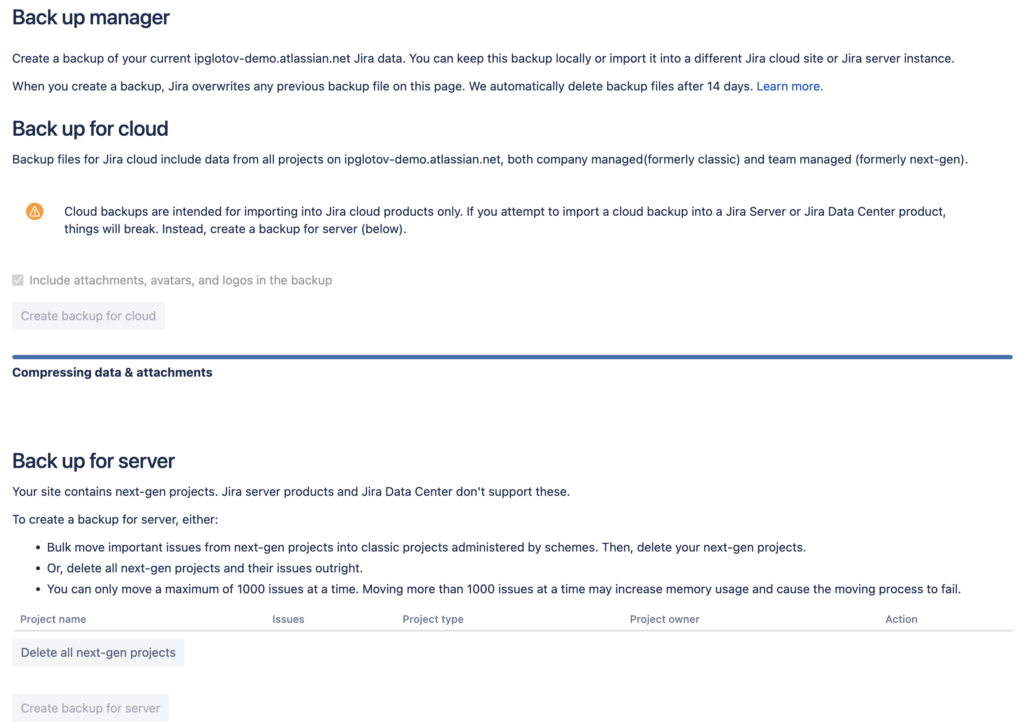
Камень 1: сделать резервную копию для сервера не получится без удаления Team-managed проектов, или их конвертации в Company-managed проекты.
даже если вам не нужны Team-managed проекты в серверной Jira:
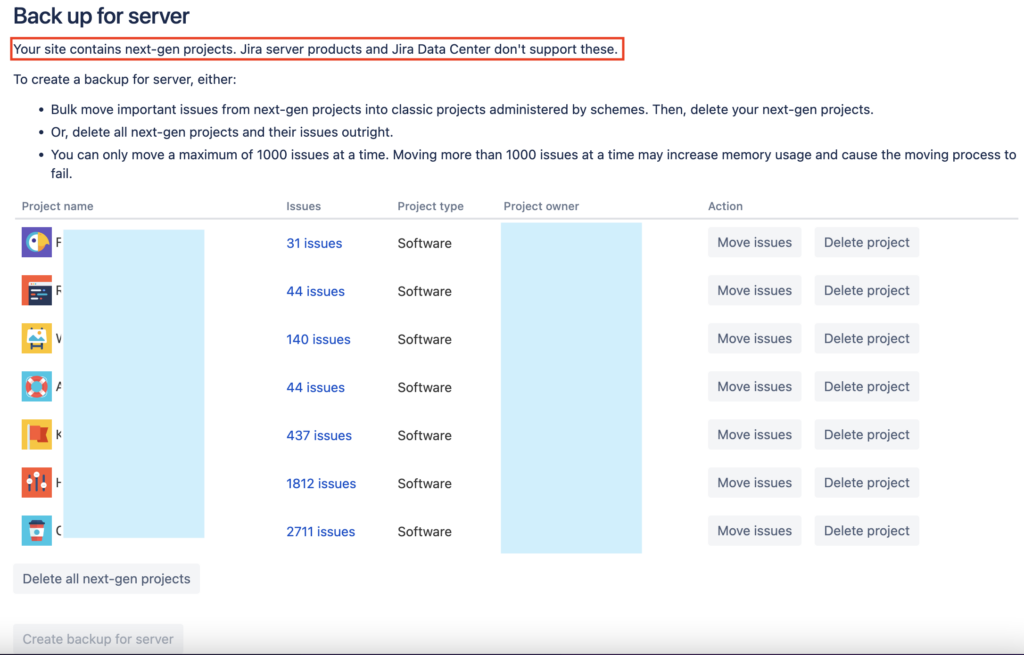
Если вы решили именно удалять Team-managed проекты, то поместить их в корзину будет не достаточно:
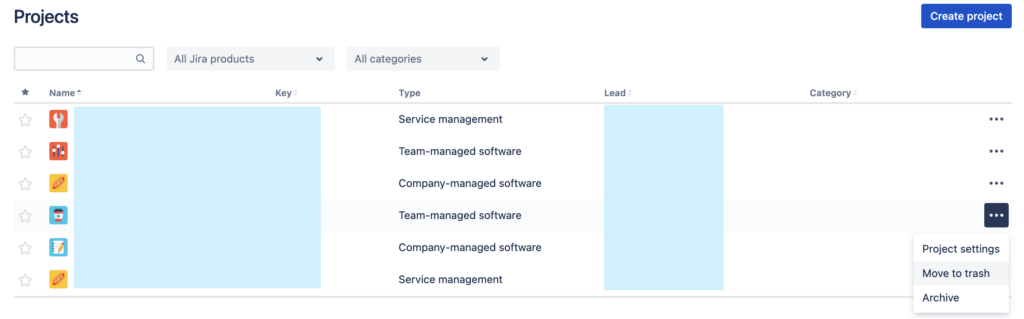
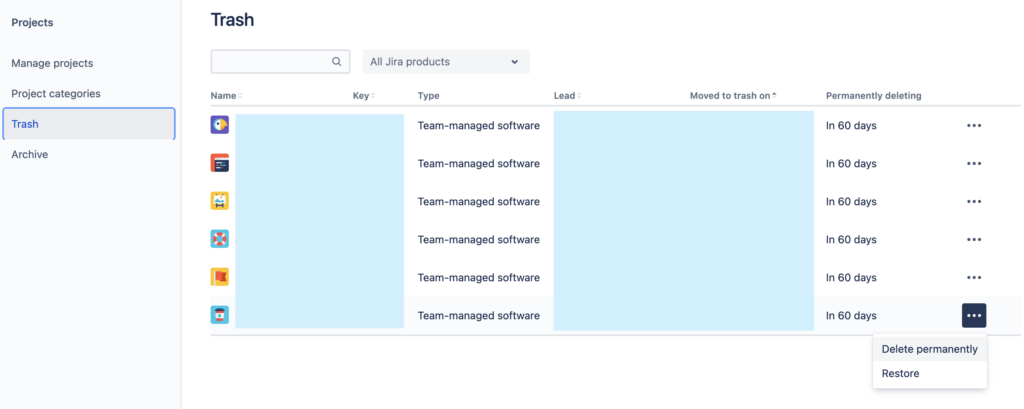
Нужно ещё и очистить корзину, чтобы никаких следов точно не осталось:
Отдельного упоминания заслуживает допустимая частота создания резервных копий: понятно, что это тяжёлая дорогостоящая операция для облака и в нормальных условиях делается ночью раз в сутки. Но при миграции иногда на нужно «докатывать» какие-то свежие изменения и с этим могут возникнуть проблемы:

Камень 2: резервную копию в облаке можно делать примерно раз в 45 часов.
Забавнее всего, если вы делаете резервную копию боевое облако-тестовое облако (например, чтобы перед миграцией на сервер что-то серьёзно модифицировать в облачных проектах, не затрагивая при этом боевое облако), то на тестовом облаке тоже обязательно нужно предварительно сделать резервную копию:
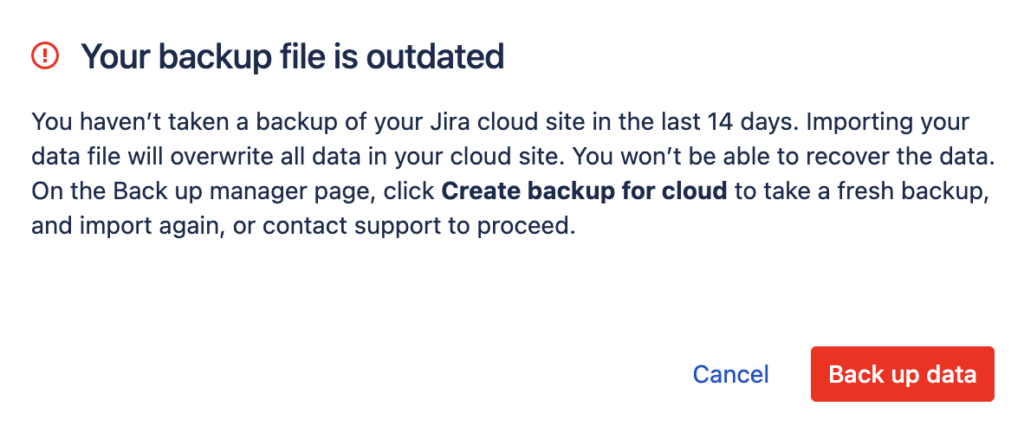
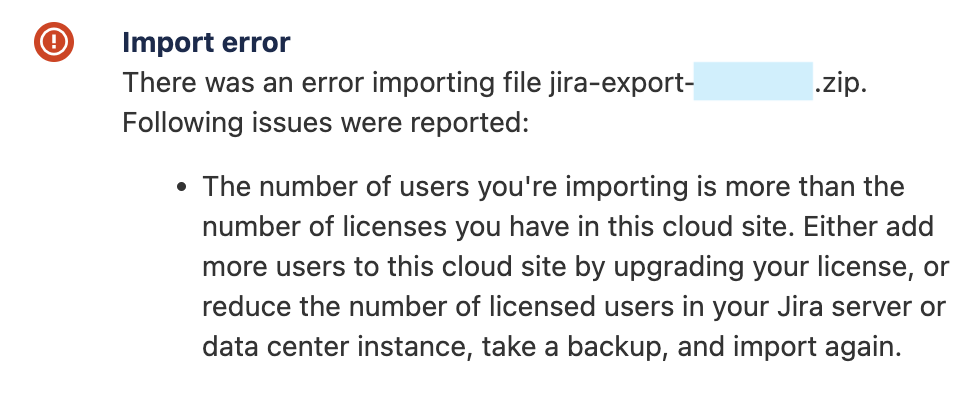
Камень 3: для восстановления резервной копии в облаке, обязательно сначала нужно сделать резервную копию (без неё на заработает).
Как понимаете, при таких ограничениях реально сделать не больше 1 переливки раз в 45 часов. И только в том случае, если резервные копии в обоих облаках делаются синхронно.
Опасно торопиться в этом процессе и запускать восстановление тестового облака до завершения его резервного копирования — можно получить зависший экран:
В моём случае поддержке Atlassian потребовалось 3 (!) рабочих дня, чтобы перезапустить зависший процесс резервного копирования.
Ещё может получиться, что в тестовом облаке число пользователей меньше, чем в боевом облаке, тогда мы получим справедливое уведомление и не сможем развернуть резервную копию:
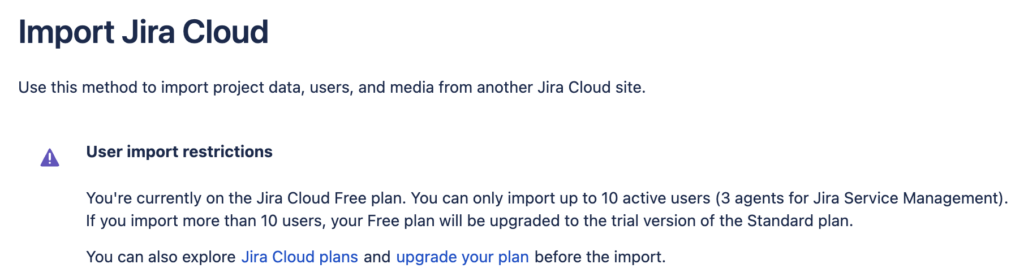
Поэтому создать бесплатное тестовое облако со стандартными 10 пользователями для нашей задачи вряд ли получится 🙁
Но чаще используется менее радикальный подход, чтобы Team-managed проекты переехали на сервер:
Шаг 1. Конвертация Team-managed проектов в облаке
1.1 создание и настройка Company-managed проекта
Сначала нужно создать Company-managed проект, в который будем переносить задачи из Team-managed проекта (для удобства выберем шаблон Kanban):
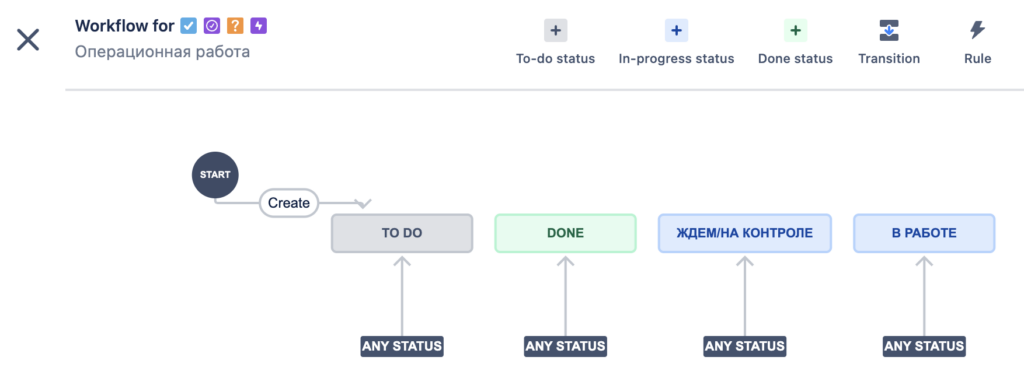
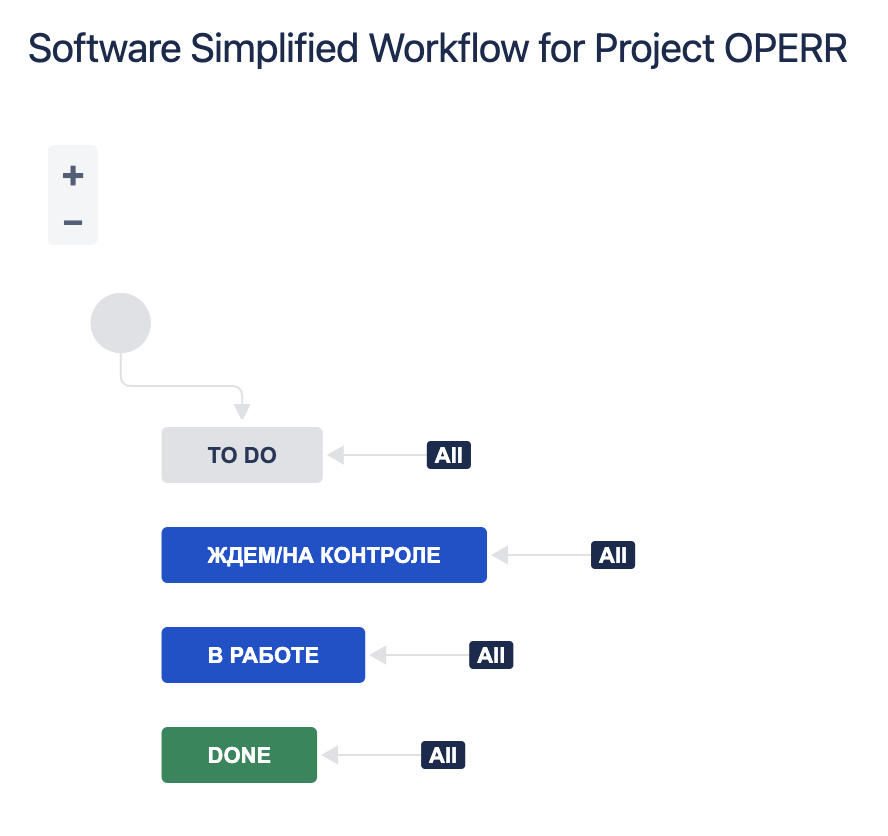
При этом важно, чтобы наборы полей и workflow обоих проектов были идентичны (нужно озаботиться этим до запуска миграции):
1.2. написание JQL-запроса
Затем нужно написать JQL-запрос, выделяющий все задачи из Team-managed проекта для последующей миграции в Company-managed проект, в простейшем случае запрос будет примерно таким:
project = MyProject
и дальнейший Bulk change их всех обработает:
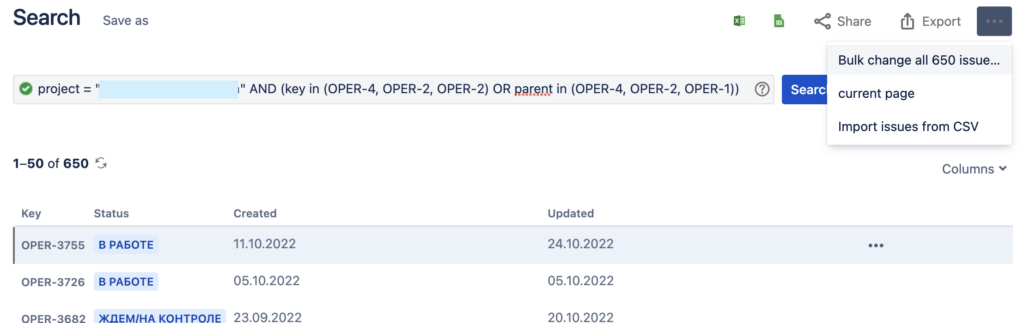
Но на практике Bulk change хорошо работает, только если в проекте меньше 1000 записей, иначе придётся делать несколько запросов:
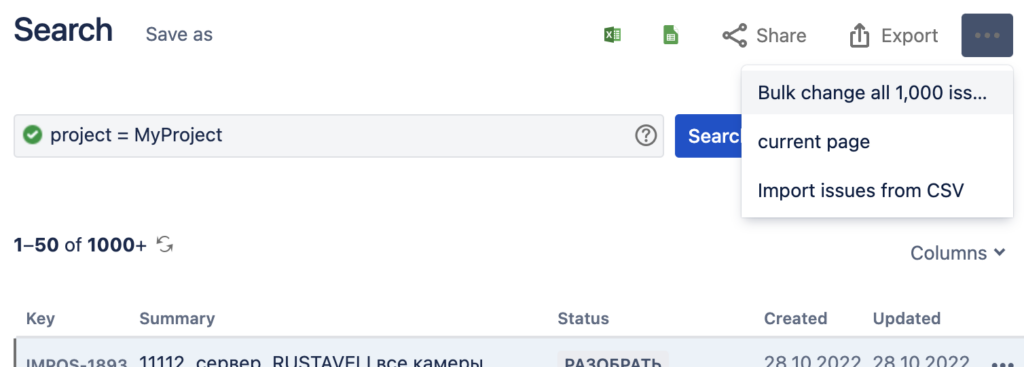
Вроде бы, проще всего написать несколько таких запросов:
project = MyProject AND key < MYPROJ-1000
project = MyProject AND key < MYPROJ-2000
...
Но тут мы сталкиваемся с особенностью Team-managed проектов:
Камень 4: чтобы не потерять связи задач с Epic-ами, и задачи и привязанные Epic-и должны присутствовать в единой Bulk change-операции.
Иначе возникнет вот такое предупреждение:
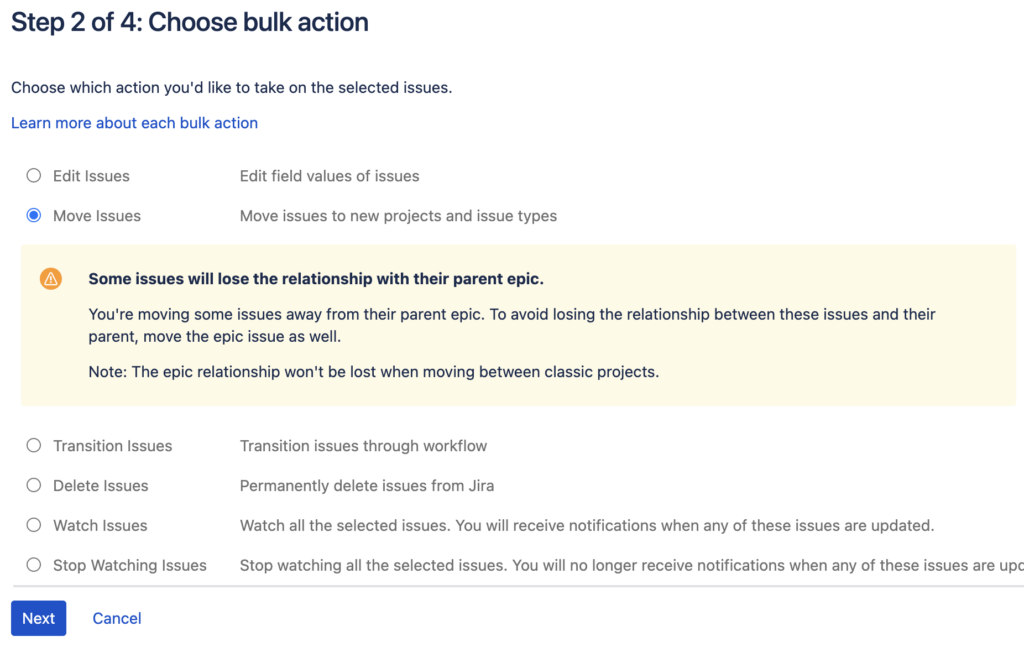
и для сохранения связей запросы придётся писать примерно в таком виде:
project = MyProject AND (
issuetype = Epic AND key in (MYPROJ-1, MYPROJ-2, ...) OR
issuetype != Epic AND parent in (MYPROJ-1, MYPROJ-2, ...)
)
где MYPROJ-1, MYPROJ-2… — ключи Epic-ов из проекта.
Ещё важно не забыть задачи без Epic-ов (бывают и такие), вот таким запросом:
project = MyProject AND (
issuetype != Epic AND parent is EMPTY)
)
Все описанные выражения лучше комбинировать так, чтобы количество задач в каждом приближалось к 1000, поэтому число самих запросов было бы минимально возможным.
После этого мы запускаем Bulk action и указываем операцию переноса задач:
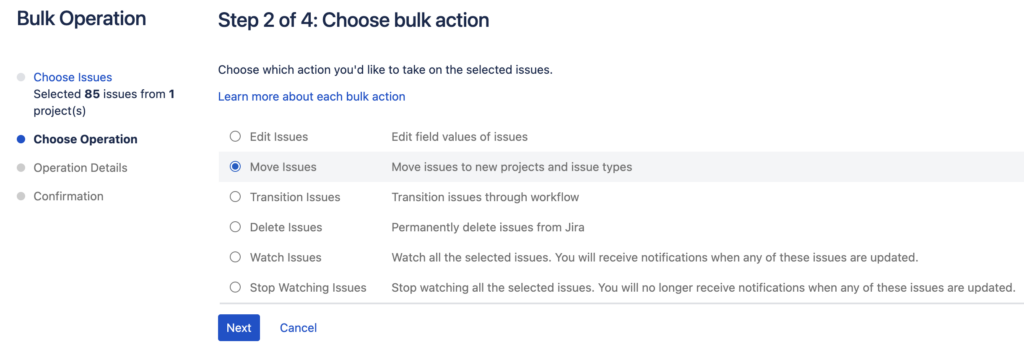
1.3 соответствие сущностей
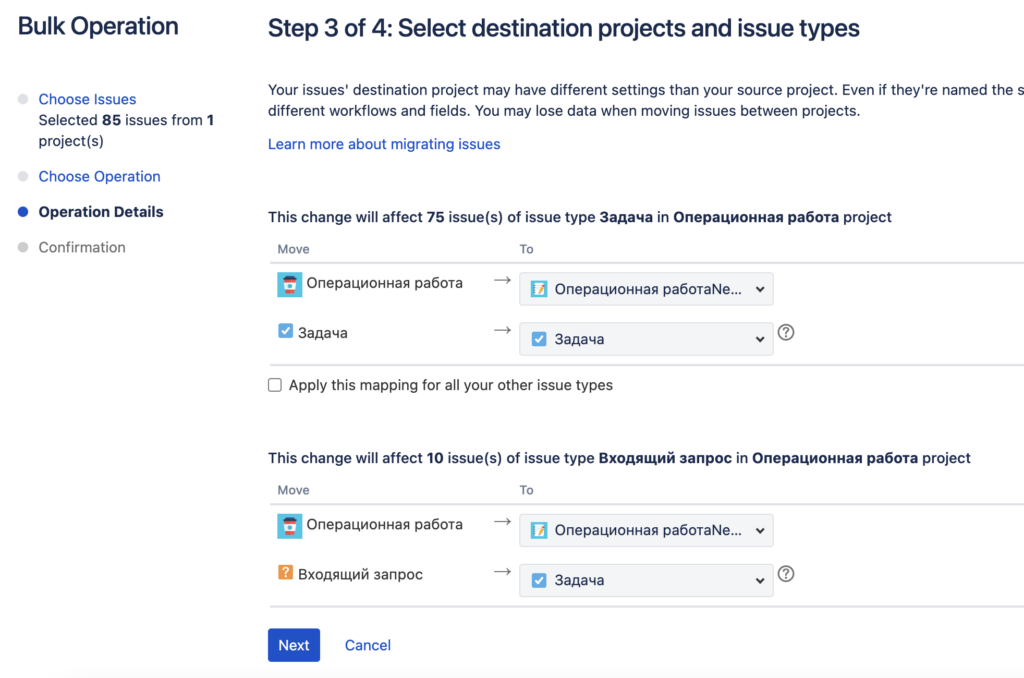
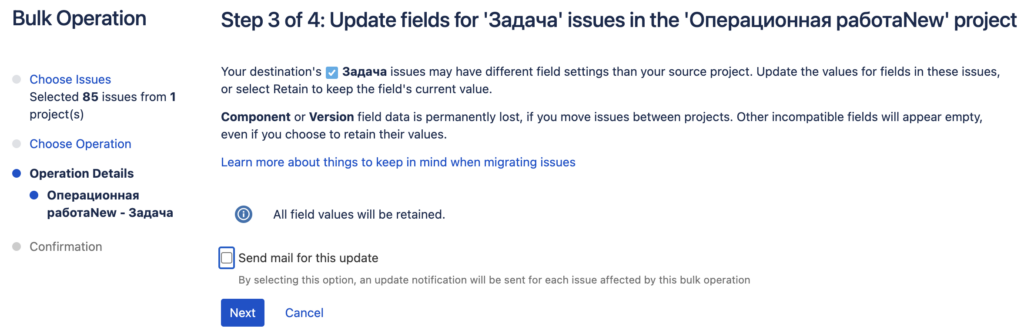
Затем идёт ручной немного муторный процесс указания соответствия между сущностями, сначала проектами и типами задач, затем статусами и уже в конце полями после чего запускается процесс переноса:

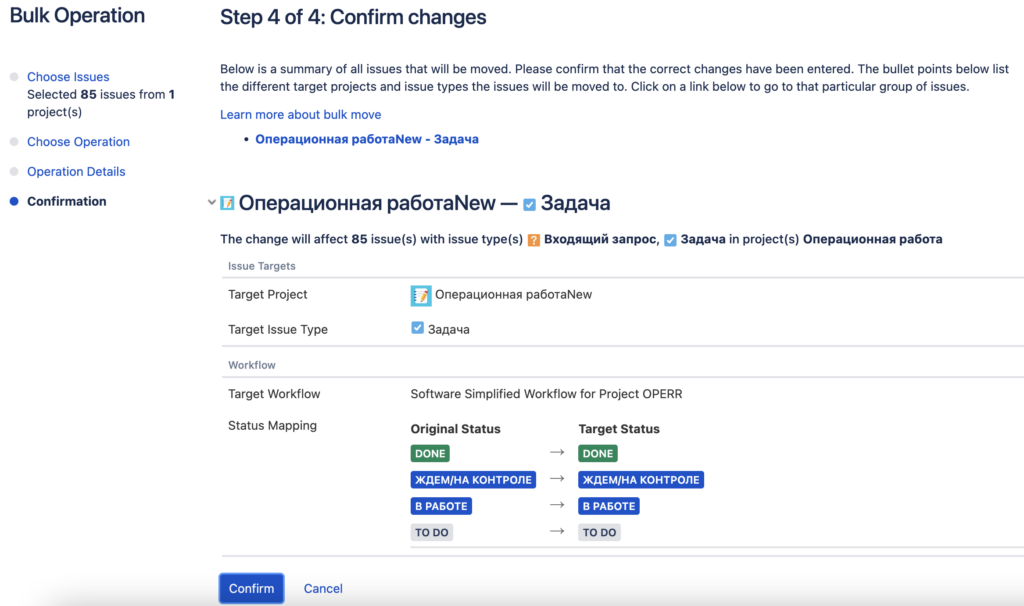
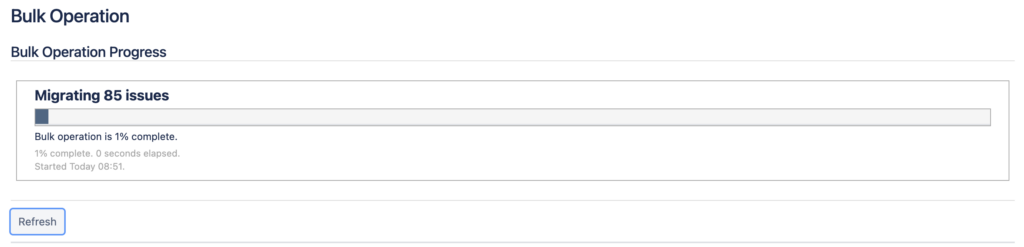
1.4 настройка досок в новом Company-managed проекте
В ходе создания Company-managed проекта обычно доска создаётся самая примитивная, при изменении статусной модели никак не изменяется, поэтому после миграции задач это нужно сделать вручную:
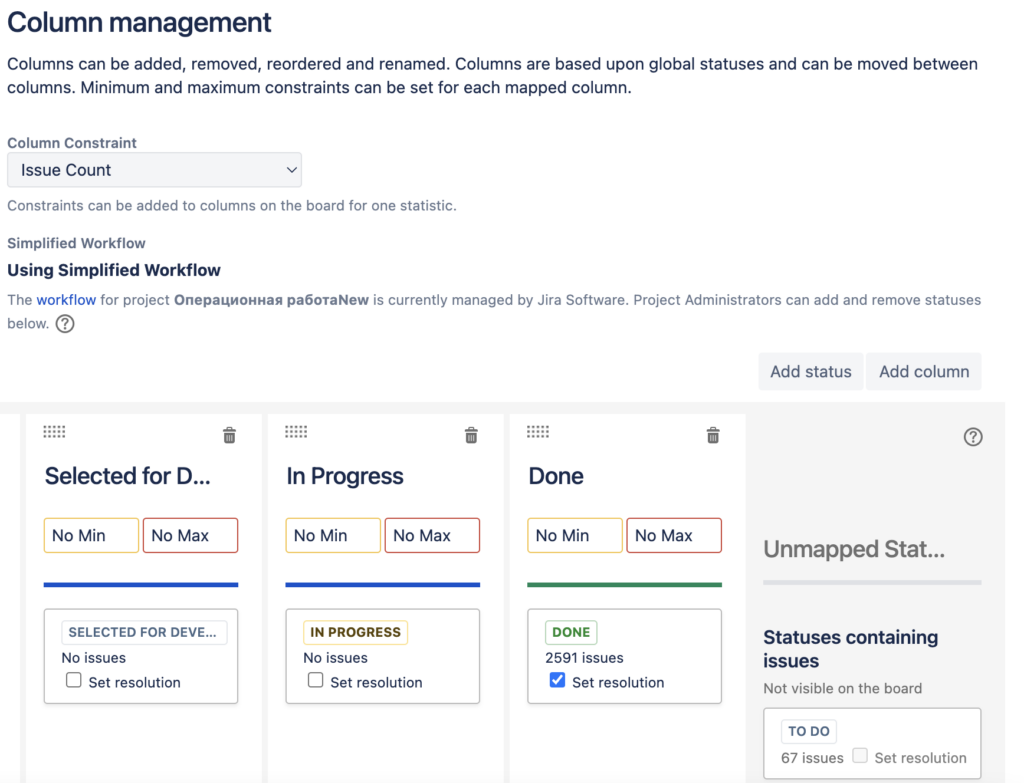
1.5 исправление ошибок после миграции
К сожалению, успешно закончившийся процесс миграции не гарантирует, что на сервере всё будет работать так же хорошо, как и в облаке.
1.5.1 отсутствие плагина пост-функции
Например, при попытке перевести задачу из одного статуса в другой возникала вот такая ошибка:
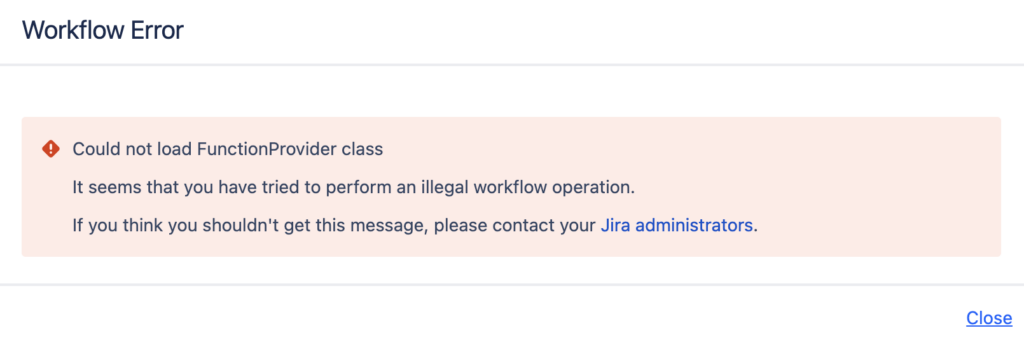
Причиной была вполне невинная пост-функция сброса поля resolution при повторном открытии задачи:
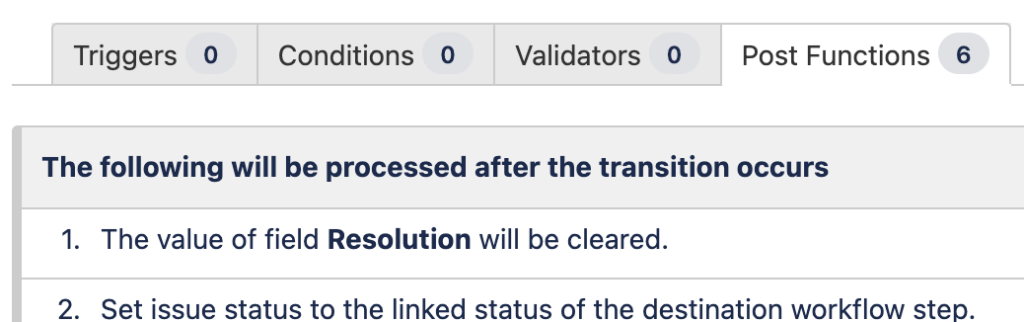
которая после миграции в облако стала выглядеть вот так:
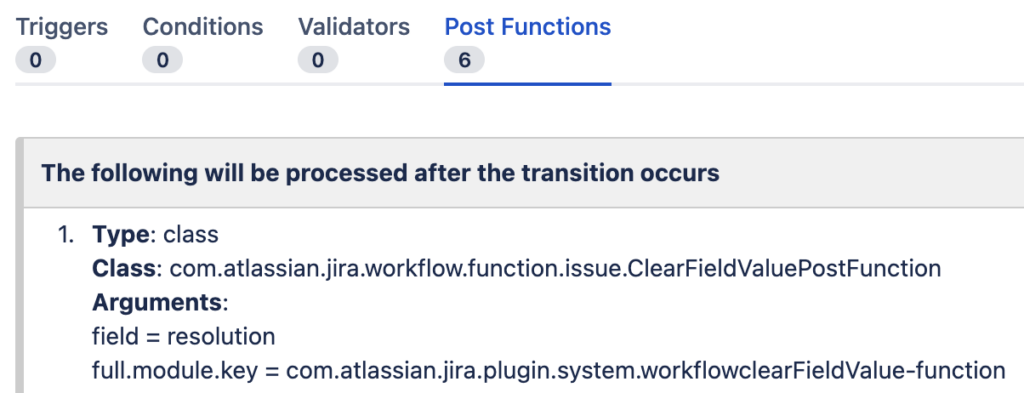
В официальной статье от Atlassian ссылаются на плагин JSU Automation Suite for Jira Workflows (старое название JIRA Suite Utilities), который похоже по умолчанию встроен в облако, но может быть не установлен на сервере (тем более, что он платный). Поэтому для решения проблемы помогло ручное пересоздание пост-функции:
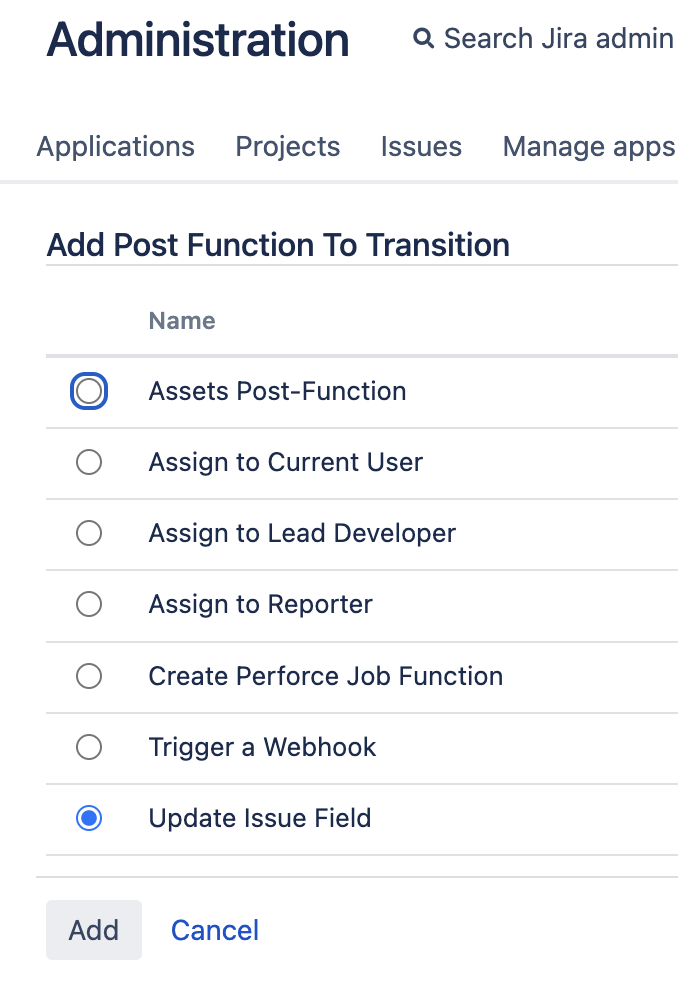
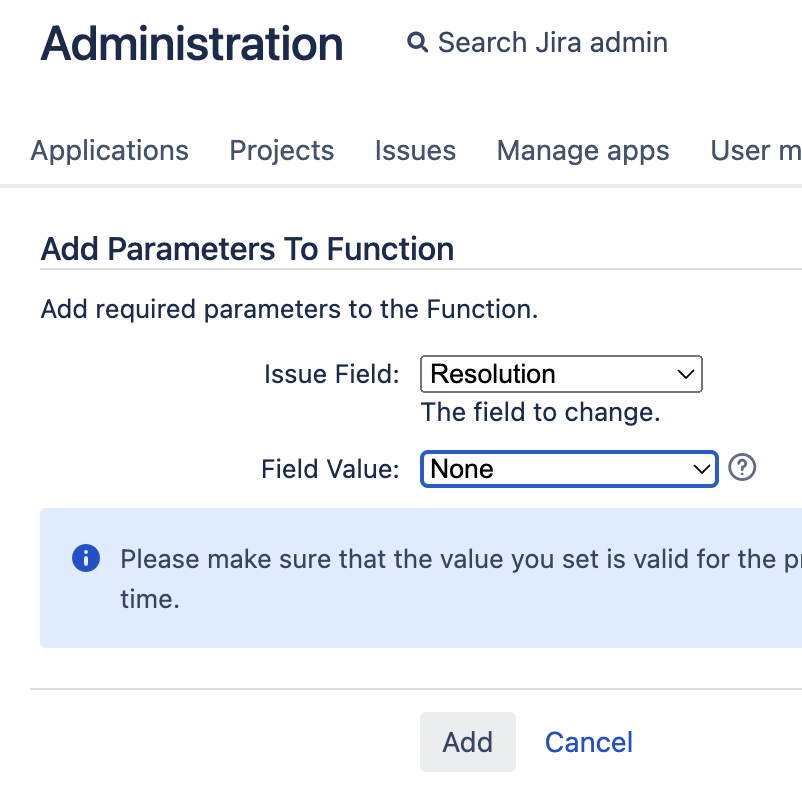
1.5.2 сбитые счётчики в базе данных
Следующая ошибка более непредсказуема и сложна для исправления — при попытке заполнить значение поля выводилось сообщение:

с такой записью в логах:
Возникло исключение: com.atlassian.jira.exception.DataAccessException: org.ofbiz.core.entity.GenericEntityException: while inserting: [GenericEntity:CustomFieldValue][parentkey,null][customfield,10111][issue,20061][stringvalue,10003][id,58607][updated,1667219395380] (SQL Exception while executing the following:INSERT INTO public.customfieldvalue (ID, ISSUE, CUSTOMFIELD, UPDATED, PARENTKEY, STRINGVALUE, NUMBERVALUE, TEXTVALUE, DATEVALUE, VALUETYPE) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) (ERROR: duplicate key value violates unique constraint "pk_customfieldvalue" Detail: Key (id)=(58607) already exists.))
Тут дело в том, что значения всех полей хранится в таблицу с непрерывной нумерацией строк, а номер самой старшей строки хранился отдельно и был равен 58606, т.е. меньшим старшего значения номера строки — из-за этого не проходила вставка в эту таблицу и возникала ошибка.
Решение описано у Atlassian и не отличается элегантностью: нужно выключить Jira, вручную обновить номер старшей строки и снова включить Jira, помогло.
Аналогичные ошибки могли возникать и для других сущностей (например, ссылок между задачами или переходами бизнес-процесса), которые в моём случае решились только удалением/пересозданием сущностей:

1.6 Миграция записей о проделанной работе (worklog или timesheet) из облачного Tempo
С одной стороны, все worklog-и вроде бы хранятся в Jira и стандартный export-import должен их корректно мигрировать. Но когда мы используем дополнительный функционал из плагина Tempo (например, описание или классификация worklog-ов по признакам billable/unbillable), его приходится переносить вручную — в моём случае через Excel, который пришлось вручную залить в новую таблицу БД Jira (worklog_artem в моём случае) и вручную обновить её структуру:
-- конвертировать облачные логины пользователей
UPDATE worklog SET author = 'artem', updateauthor = 'artem' WHERE author IN ('addon_is.origo.jira.tempo-plugin', 'addon_io.tempo.jira') OR updateauthor IN ('addon_is.origo.jira.tempo-plugin');
-- обновить описание worklog из Excel
UPDATE worklog w
SET worklogbody = g."Worklog"
FROM jiraissue i, worklog_artem g
WHERE i.id = w.issueid AND g."Key" = 'PROJ-' || i.issuenum AND g."Logged" * 3600 = w.timeworked AND w.startdate = to_timestamp(g."Date", 'DD/MM/YY at hh24:mi')::timestamp with time zone at time zone 'GMT+3' AND i.project = 10000 AND (w.worklogbody = 'time-tracking'); -- приходится закладываться на даты и размер worklog, т.к. никаких идентификаторов Tempo не даёт
Вывод
Облачные продукты прекрасны, но только до момента, пока вы не решите переехать с них на self-hosted решение.
Вроде бы всё предсказуемо, очевидно и банально до простоты, но в последние пару месяцев пришлось столкнуться с абсолютно разными подводными камнями, которые возникают неожиданно и вроде бы неоткуда, чем затрудняют оценки по проекту и увеличивают его стоимость — желаю всем как можно аккуратнее обходить эти неожиданные трудности!